

Making DNA: The Quest for Synthetic Life
Making DNA: The Quest for Synthetic Life
Cells with synthetic genomes could build almost anything. Managing biosecurity risks is another story.


Welcome to Codon, a newsletter about the bio+tech advances enabling a brighter future for humanity.

In 2019, Georg Tremmel and Shiho Fukuhara, two artists in Tokyo, built a “Black List Printer;” a DNA synthesis machine that creates strictly ‘forbidden’ sequences, like bits of pathogens and chunks of viruses.
“The physical DNA is outputted within water droplets, which are embedded and dried on paper,” the artists wrote. “DNA is continuously synthesized, printed, and archived on the paper, creating a pool of forbidden DNA sequences — but most of them will not be printed perfectly — they will have errors and mutations.”
Their device, called the BLP-2000D, was an artistic experiment, designed to probe the moral fabric that underlies DNA synthesis. “Should we stop DIY DNA Synthesisers in the name of biosafety?” the artists wrote.
“Can we stop them?”
In the last decade, our ability to build custom DNA has increased by at least an order of magnitude. It has never been easier to print sophisticated, error-free DNA sequences. But with rapid progress comes an array of biosecurity risks, and efforts to regulate the technology have lagged behind its development.
A growing cadre of companies are selling DNA printers that could soon manufacture gene length sequences on-demand. The Army and a small number of companies are concerned about the concomitant risks.
“If you could print something that long, it would really lower the barrier and the amount of technical skills needed to assemble something pretty impressive,” says Nicole Wheeler, a Turing Fellow at the University of Birmingham who develops biosecurity software. “So the concerns around the security implications of those capabilities are pretty serious.”
The U.S. military is also concerned about growing competition from China. Integrated DNA Technologies, a DNA maker in Iowa, solely makes their sequences at U.S. facilities. Other companies swear “up and down” that they do the same, says Randall Hughes, who runs the Army’s Biofoundry in Austin, Texas, but others have offshored their DNA manufacturing to China.
Proprietary DNA sequences are being made abroad, says Hughes, and that means “someone could easily reconstruct your blueprints.”
Biological engineers are fast approaching the ability to make synthetic genomes and custom lifeforms in a genuflection to Richard Feynman’s mantra: “What I cannot create, I do not understand.” But they must find ways to balance progress with the biosecurity risks.
This essay explores the storied past and uncertain future of synthetic genomes. It considers emerging technologies to make gene-length DNA sequences and stitch them all together. It explores fresh tools to predict how genes will behave in a living cell. And it dreams of what humanity might achieve if new-to-Earth organisms are built cheaply and at scale — while averting disaster.
Organisms with manipulated genomes already convert factory emissions into methanol and fuels, produce the global supply of insulin, and manufacture most COVID-19 vaccines. Their role in society will continue to expand.
Despite rapid engineering progress, though, we still lack the tools to build entirely synthetic organisms that behave as expected. Genome synthesis is both technically and financially difficult, a pursuit reserved for the largest and most luxurious labs. And even if one could easily build a bespoke genome, it is excruciatingly difficult to predict how genes will behave when arranged in original ways.
We stand, today, at the precipice of newfound capabilities. Now is the time to be transparent about synthetic genomes, and consider the threats that synthetic DNA poses.
Advances come fast. An international team, spanning at least eight countries, is nearly finished making a synthetic, man-made version of all 16 yeast chromosomes. The team will soon assemble the pieces and boot up the first eukaryotic cell with an unnatural genome.
Meanwhile, at Harvard University, scientists working under George Church have spent the last ten years “recoding” the genome of Escherichia coli, a simple bacterium, to shrink its genetic code from 64 to 57 codons. The engineered organism will be entirely resistant to viral infections; final results will be published soon, according to people familiar with the project.
In the future, we dream of still more ambitious aims, like seeds re-wired to blossom and grow into fully-formed homes, complete with a kitchen, walk-in closet and two bathrooms. (Picture Galadriel’s tree, from The Lord of the Rings.) Synthetic bacteria, blasted to Mars, could terraform the Red Planet — no small feat, given the dearth of water and temperatures that routinely fall below -10 degrees Celsius, where Earth-like cells cannot divide.

The possibilities of bespoke genomes are limited only by imagination, and it’s imperative that we build the tools to make them a reality. Evolution moves too slowly to keep pace with our destruction of the planet — climate, rising seas, smog, scarce food in resource-starved areas, and pollution. Engineered biology can help, but two major advances are first required.
We desperately need new technologies to build any DNA sequence, including very long ones, while sniffing out pathogenic materials. And we need algorithms that accurately predict how DNA will behave in a living cell when arranged in unique ways. Both are remarkably difficult, but not impossible.
Read on to learn about:
Storied Pasts: From humble beginnings to international meetings, DNA synthesis has come a long way since a gene was first synthesized in 1972. Fifty years later, more ambitious projects are in the works.
Stitching Molecules, Weighing Risks: Little machines will soon build DNA strands with thousands of bases. Biosecurity experts worry about the risks.
From Letters to Life: Once a DNA sequence is crafted, algorithms must predict whether it will ‘boot up’ within a living cell.
Biology’s Future: New-to-Earth lifeforms could make almost anything. A new Human Genome Project would catalyze the mission.
Storied Pasts
This is a good time to be alive. People today are generally living longer, healthier lives than at any other time in human history. A hundred years ago, infectious diseases like pneumonia and tuberculosis were leading causes of death. By the end of the 20th century, they accounted for 4.5 percent of deaths. Smallpox killed an estimated 300 million people after 1900, but was eradicated by 1980. More than 23,000 animals were slaughtered to make one pound of insulin in the early 1980s, enough to help 750 people with diabetes for one year.
Genetic engineers have made incredible strides in health and medicine over the last forty years. Insulin and most vaccines are now produced by genetically altered cells. Engineered cells can synthesize anti-cancer drugs, detect water contaminants, or store massive datasets in DNA. Many of society’s greatest leaps are borne from the fruits of biotechnology, especially our ability to read, write, and edit DNA. This essay, of course, is all about that middle bit.

In 1972, Har Gobind Khorana, a biochemist at the University of Wisconsin-Madison, used chemistry to assemble just 77 base pairs of DNA. The short sequence encoded a gene for tRNA, a molecule that carries alanine amino acids to ribosomes during protein construction. A few years later, Khorana and his team extended this sequence to 207 base pairs by tacking on a promoter and terminator, elements that help the sequence to be expressed in living cells. When they dropped this sequence into a bacterium, it worked much like a natural piece of DNA, and the engineered cells made the synthetic tRNA.
Khorana’s achievement, in August 1976, made the front page of the New York Times. But it took Khorana and his team — two dozen scientists in total — nine years to build this tiny gene, or 200 person-years total, according to Stephen Hall’s classic book, Invisible Frontiers. The tools to build DNA were clearly slow, painful, lacking.
Thirty years after Khorana’s feat, as scientists scrambled to sequence the human genome, the J. Craig Venter Institute (JCVI) rose to dominate the then-niche area of DNA synthesis. A non-profit research institute nestled in the soft hills of La Jolla, California, JCVI was founded by American biotechnologist, J. Craig Venter, and its scientists were the first to make a full genome with synthetic DNA. The whole process took less than 2 weeks, and the small genome was built from 259 short pieces of DNA. It spanned 5,400 bases in length and encoded the full genome for a bacteriophage, called φX174.
JCVI’s achievement was only possible because molecular biology had advanced so much in the decades prior. Kary Mullis’ invention of the polymerase chain reaction, or PCR, meant that strands of DNA could be easily multiplied. Scientists had also migrated to phosphoramidite chemistry for DNA synthesis. Invented by Marvin Caruthers, a Khorana protégé, in the early-1980s, it offered a quicker and more efficient way to build small pieces of DNA.
In 2005, three biologists at MIT pushed the frontiers of synthetic genomes further still. Beginning with a bacteriophage called T7, they replaced 11,515 letters, or roughly half of its entire genome, with a synthetic version. The semi-synthetic bacteriophage was largely unaffected by the changes, again bolstering the thesis that artificial DNA works the same as anything from nature.
The paper’s authors — including Drew Endy, now at Stanford — were keenly aware of its importance. “Our work with T7 suggests that the genomes encoding other natural, evolved biological systems could be redesigned,” they wrote, “and built anew in support of scientific discovery or human intention.”
This was the inflection point for a radical new vision in biology. Dreams of genome synthesis swelled inside the hearts of young biologists. New plans were drawn up to create larger genomes, or entirely new types of living organisms, by stringing together DNA fragments. The fledgling field of “synthetic genome engineering” — which, unlike genetic engineering, aims to manipulate genes across an entire genome, according to Tom Ellis, professor at Imperial College — had officially taken off.
By 2008, JCVI had built the first synthetic, bacterial genome. The ensuing paper, published in Science, explained how 582,000 base pairs of DNA encoding a Mycoplasma genitalium genome had been assembled in test tubes. This naughty-sounding bacterium was singled out for DNA synthesis because its genome is about five times smaller than E. coli’s. But, when the JCVI team finished making the genome and placed it into cells…nothing. After more than a decade of work, the team was “unable to activate [the] genome in a cell.”
Just two years later, the problem was resolved when a longer version of the synthetic genome, stretching over 1 million base pairs, was transplanted into a similar bacterium, called Mycoides capricolum. The bacteria had, in effect, undergone a genome transplant; its native genome was stripped away and replaced with the synthetic version for M. genitalium. The new cells booted up and were successfully “controlled only by the synthetic chromosome,” the authors wrote. “The only DNA in the cells is the designed synthetic DNA sequence…[and] the new cells…are capable of continuous self-replication.”
This, the first bacterium powered by a synthetic genome, was dubbed JCV-syn1.0. It cost $40 million to make.
After their achievement, the JCVI team made a surprising decision. Instead of building larger genomes, they said, JCVI would instead create a “minimal cell” that contains only those genes essential for life. The achievement would herald a new age in biology; if we truly “understand the molecular and biological function of every gene in a cell,” the JCVI team wrote — the minimal amount of stuff needed to sustain life — then we will know, in detail, how to build life anew.
By 2016, JCVI succeeded in its mission. Kind of. A genome-minimized strain, called JCV-syn3.0, self-replicates and contains just 473 genes, or about one-tenth the number of genes in E. coli. Despite its small size, though, a whopping 149 genes had unknown functions. In the years since, the JCVI has been systematically annotating each gene, and its function, in this synthetic cell. A more recent strain contains just 452 protein-coding genes and, as recently as 2021, a collaboration between JCVI and MIT identified functions for five additional genes required for cell division.
As JCVI worked toward minified genomes, academic groups formed teams and raised millions for moonshot projects. More than anything, these academics convinced grant funders that there are massive, industrial upsides for synthetic genomes.
E. coli and yeast already manufacture billions of dollars worth of valuable molecules — medicines, biofuels, and materials — each year. In the past 38 years, though, there have been at least 26 virus contaminations at biomanufacturing facilities. Viruses get inside bioreactors and infect cells. (In the early 1980s, some people with hemophilia who were given plasma were unknowingly infected with HIV.) By building synthetic genomes, then, these issues could be avoided; E. coli or yeast genomes could be genetically altered to become ‘unreadable’ by invading viruses.
In 2013, the first step toward this aim, the redesign of the E. coli genome, was reported in the journal Science. Each of the cell’s 321 UAG codons — which signal a ribosome to stop making protein — were replaced with UAA, endowing the semi-synthetic cells with “increased resistance to T7 bacteriophage,” according to the paper.
This redesigned bacterium was not inherently synthetic — just 321 bases, out of 4.6 million, were actually changed — but the study is important because it made changes across the entire genome, rather than in a single place. It demonstrated — just one year after Doudna & Charpentier’s famous CRISPR gene-editing paper — that biologists could systematically alter an entire genome at multiple locations.
Synthetic genomes took off like a rocket. In 2019, a group at Cambridge University constructed a fully synthetic E. coli genome, with three codons removed, from nearly 4 million bases of DNA. That same year, a team from Switzerland built the full 786,000 base genome of Caulobacter ethensis, a computer-designed organism adapted from a freshwater microbe, called Caulobacter crescentus. The team rewrote a total of 123,000 codons, or 383-times more than the 2013 Science paper.
American geneticist, George Church, is now working toward an E. coli genome that contains just 57 codons. The cell, called rE.coli-57, is a decade in the making and will be resistant to all phage infections. It could also build proteins with nonstandard amino acids — outside the canonical twenty — to vastly expand the types of molecules that are manufactured from living cells.
Akos Nyerges, a postdoctoral fellow in the lab, is leading that project. In the last three-and-a-half years, he says, “DNA synthesis has improved a lot.” But troubleshooting organisms — and measuring whether the synthetic genomes actually work as expected — has not improved much. Nyerges expects to unveil the 57-codon E. coli paper soon; probably this year.
Larger genome synthesis projects are also underway, including the Synthetic Yeast 2.0 project. A global consortium, spanning at least eight countries, is making artificial versions of all 16 chromosomes in Baker’s Yeast, plus an additional ‘neochromosome’ that holds solely tRNA genes.
This project, once complete, will herald the first synthetic eukaryote. Each gene in its genome has been flanked with little snippets of DNA, called loxP sites, that can be snipped out and “scrambled” around the genome at will. But otherwise, the synthetic genome looks much like its natural version. Chromosome 3 was the first to be synthesized, in March 2014, and the neochromosome was finished in 2022. The project is expected to finish this year or next.
(In 2016, a Chinese team also fused all sixteen yeast chromosomes into one big “mega chromosome.” The organism grew a bit slower, but was largely unaffected by the ordeal.)
What can we take away from this history? Admiration, on one hand, and concern on the other. In just fifty years — since the days of Khorana — DNA synthesis has come down in price, and ramped up in speed, by orders of magnitude. A slew of companies, such as IDT and Twist, can ship custom-made DNA sequences to research laboratories overnight. We went from Endy’s half-synthetic phage, in the early 2000s, to entire synthetic genomes by the mid-2010s. Global efforts, like the GP-Write Consortium, now aim to reduce the costs to build large genomes “by 1,000-fold within ten years.”
But not everything is rosy. Genome synthesis remains the rarefied pursuit of wealthy labs and large consortiums. It can cost millions of dollars — and 100+ person-years of time — to build a single genome. Most labs, of course, cannot do this. Until genome synthesis is democratized — via cheap DNA, longer sequences, and easier tools to assemble the fragments — we won’t see exponential progress toward custom-made organisms.

Stitching Molecules, Weighing Risks
There are two ways to make DNA: The old and the new. One harnesses chemistry, the other biology.
The old school approach rose to prominence in 1981, when a pioneering biochemist named Marvin Caruthers made, at the University of Colorado Boulder, a precise sequence of DNA — ‘CGTCACAATT’ — from individual, chemical building blocks. His technique, called phosphoramidite chemistry, is still the method of choice for most DNA synthesis companies. It works like this:
Attach a single DNA letter (A, T, C, or G) to a solid surface, such as glass or silicon. Wash this molecule with trichloroacetic acid to strip away a few atoms. The ‘naked’ letter can now join with another. The next base in the sequence is added to the pot, and the two ‘click’ together. In a final step, the two-letter sequence is oxidized and protected to block additional letters from joining by mistake. Everything is washed away. The cycle repeats anew, step by methodical step, until a full sequence has been crafted.
This three-step process seems simple in principle, but is plagued by inefficiencies. Each step produces waste and relies upon hazardous chemicals. Each step also runs the risk, however small, of an error; one misplaced letter is enough to kill a gene.
A pioneer in DNA synthesis, Integrated DNA Technologies, sits in a short brown building amidst the rolling hills of eastern Iowa (I went to school just a few miles away, in Iowa City). The company has been making DNA with the Caruthers method since 1987 and their most optimized approach, today, is about 99.6 percent accurate at each letter.
An accuracy near 100 percent may sound quite good on paper, but it’s nowhere near good enough. The longer that a DNA sequence gets, the more likely that it will be wrong (only about half of sequences in a tube with a 120-base sequence of DNA are correct.) A typical sequence made with the phosphoramidite method is thus limited to about 200 nucleotides. Low accuracy, and short sequences, is not a big deal for most molecular biology experiments, like PCR. But it’s stifling when it comes to building a genome, where every letter must be correct.
The Caruthers method has been around for decades and was fully automated shortly after its invention in the 1980s. You can still buy an old-school DNA synthesis machine, the MerMade 192X Synthesizer, online. And yet, despite its age, phosphoramidite chemistry is still the dominant method behind most of the world’s synthetic DNA. Billion-dollar companies continue to iterate on the technique.

In 2013, for instance, Twist Bioscience took a pioneering leap: Instead of making one DNA sequence at a time, what if one could ‘print’ DNA strands on a two-dimensional array?
The San Francisco-based company did exactly that. They use a fine-tuned printer head, loaded with nucleotides, to sculpt thousands of sequences at once with very little waste.
Another company, Evonetix, has built a silicon chip that can also make thousands of DNA strands in parallel. Electrical pulses move each sequence from one reaction site to another. But despite their advances, the price for DNA has not fallen much.
From 1991 to 2017, the price to make a short strand of DNA fell by an order of magnitude, from one dollar per base to a little under ten cents, according to data from Rob Carlson. Meanwhile, the cost to sequence DNA fell from more than ten dollars per base, in 1990, to thousandths-of-a-penny today — more than eight orders of magnitude.
The short sequences, made by Twist and IDT, are part of a $5B+ market. But this market is changing; the winds are blowing from old to new. Biologists increasingly need long sequences of DNA to engineer organisms in complex ways, and a growing cadre of companies want to sell it to them.
At least ten companies, including Telesis Bio, Nuclera, Camena and Ansa Biotechnologies, have pioneered ways to make custom, gene-length DNA strands at scale. These genes can then be stitched together to build entire genomes that power synthetic lifeforms.
Each of these companies is built atop a common foundation. Instead of building sequences through individual, error-prone reactions (like Caruthers), these startups use exquisite enzymes, harvested from nature, to make super-long strands that extend, possibly, to thousands of bases.
Sebastian Palluk is one of the shooting stars behind this nature-inspired approach to DNA synthesis. Just a few years ago, as a bioengineering PhD student in Berkeley, he was engineering E. coli bacteria to degrade plastic. But his project required long genes, and those were difficult to come by.
"Imagine if, in the software industry, it took 3 months to compile code," he says. There may have been no Oracle or PayPal, no Google or Microsoft. The startup scene would be depleted. Only monopolies would have the time and money to design and roll out products.
That metaphorical nightmare is the actual, current state of biotechnology. Long DNA sequences are still out of reach for most labs. Palluk often waited months for a synthetic gene to arrive. As his Ph.D. ticked by, he sat in Berkeley, yearning to test his ideas.
So Palluk shifted focus and did what any good entrepreneur does: Invent a solution to solve your problem. In late 2018, he co-authored an article in Nature Biotechnology that showed how an exquisitely designed protein could build custom-made DNA sequences; no chemistry required. Shortly after, Palluk launched Ansa Biotechnologies with a fellow student, Dan Arlow. The duo closed a $68 million Series A in April 2022.
Ansa wasn’t the first company to harness enzymes for DNA synthesis. They had, instead, dived into a heated arena with quickly growing incumbents.
The other companies, like Nuclera, TelesisBio, and Paris-based DNA Script, also use enzymes to make DNA. Each of these companies already sells DNA printers, too, which use enzymes to churn out custom-made sequences in a single day. DNA Script closed a $200 million Series C in early 2022 and reported, as early as 2018, that they could synthesize a 150-nucleotide strand of DNA with 99.5 percent accuracy at each position, thus rivaling IDT’s accuracy. Another company, Camena, previously reported that their enzymes can make DNA strands with 300 or more bases with 99.9% efficiency.
But there is a key difference between Ansa and the others.
The incumbent DNA synthesis companies use an enzyme called terminal deoxynucleotidyl transferase, or TdT, to add bases to a DNA sequence without using a template. Each letter — A, T, C and G — is chemically modified with a ‘terminator’ group that stops synthesis from running amok. Letters are added to the mixture, one at a time, and TdT adds each of them to the growing strand.
Ansa took the opposite approach. Instead of using chemically-modified nucleotides, Palluk and Arlow engineered the TdT enzyme directly. A molecular tether, or rope, holds the enzyme to each letter. When a base is added to the growing sequence, the enzyme’s physical bulk blocks new letters from joining. This is clever engineering, and talented writers (especially Michael Eisenstein) have covered the molecular nuance in more depth than is warranted here.
The key advantage of Ansa’s approach, we’d wager, is cost. Chemically-modified nucleotides are expensive; Ansa doesn’t use them. Over the last twenty years, gene synthesis went from about 20 dollars per base to a few cents. But this drop is not enough. A typical human gene is between 10 and 15 thousand bases in length (with lots of wiggle room), so a synthesized copy would cost about $1,000. The full human genome has three billion bases and would cost about $300 million to make from scratch (not bad, considering the Human Genome Project cost $2.7 billion).
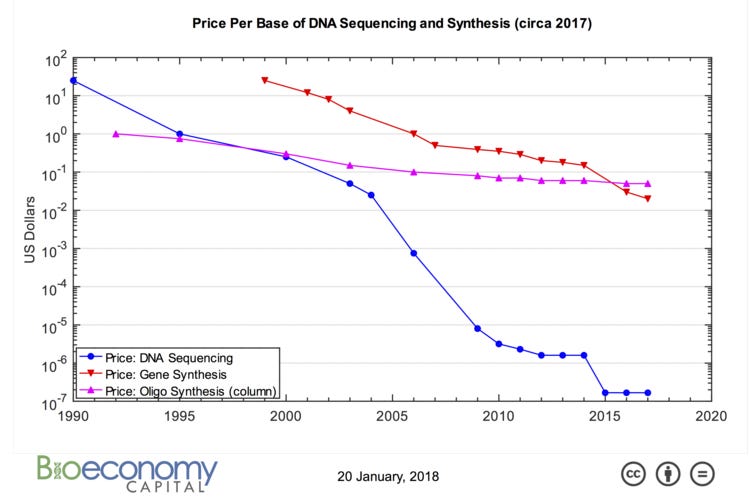
Costs aside, enzymes have unshackled the length limits of DNA synthesis. Last year, the CEO of Molecular Assemblies boasted that his company’s enzymes could “produce especially long DNA sequences,” but refused to say just how long. “Theoretically, enzymes could go to thousands of bases,” says Hughes. It’s likely that some companies can already produce DNA sequences with several thousand bases, using their enzymes, but most are moot on details and generally wary to give competitors any whiff of rampant progress.
There’s another key difference between Ansa and the other enzymatic synthesis companies, too: Ansa has no plans to sell DNA printers. Their intention, instead, is to act as the Amazon of Genes, keeping the technology in-house and shipping out DNA to laboratories. That decision bucks the trend of the other companies and is motivated, in part, by fear: DNA printers, in the wrong hands, could be used to make pathogenic organisms.
The SARS-CoV-2 virus genome is less than 30,000 nucleotides in length. Ebola virus; less than 20,000 nucleotides. HIV is smaller still; its genome has less than 10,000 nucleotides.
Although it’s technically difficult to assemble gene-length sequences from short oligonucleotides, such as those made with the Caruthers method, it is far easier to make pathogens if the whole sequence can be churned out on a printer in just a few days.
“We’re worried now because [DNA] printers are so much better,” says Palluk. “It’s easier to make 30kb.”
There are also no laws, in the U.S., mandating how companies actually screen for pathogenic DNA sequences. Each company basically pledges to follow guidelines crafted by the International Gene Synthesis Consortium, and then “develop their own screening tools in-house,” Wheeler says. “Companies are spending money [on biosecurity], but they don't have a lot of assurance that they're doing what they need to do.” The screening algorithms used by companies are also, often, proprietary.
“We don’t know how they screen, because it’s secret,” says Wheeler. “So it's unclear whether the screening is good or not.” Ansa may, in the future, use ACLID.bio to screen for pathogenic sequences. The Intelligence Advanced Research Projects Activity, or IARPA, also allocated millions of dollars in 2018 to fund computational tools that could “rapidly assess the function of DNA sequences to determine if they pose a threat.”
Benchtop synthesis devices are especially concerning because they will soon be capable of “printing between five and seven-thousand bases,” according to Wheeler. “Governments are aware of this. And, for those types of devices, they're seriously considering whether they need to legally require a certain type of screening to be performed on them, just to make sure that we don't let these capabilities out into the world.”
The DNA printing companies have responded with a simple retort: The devices only work if they are connected to the internet, and each device comes preloaded with pathogen screening software. But internet connections are not a fireproof way to stop bioterrorism. There are entire online communities devoted to hacking the ink cartridges in an HP printer, or rewiring Illumina sequencers to steal diagnostic data.
There is a tradeoff, then, between convenience and security. How do we build long genes to accelerate pioneering research, while keeping those capabilities away from would-be terrorists? This is one of synthetic biology’s next great challenges, and it’s appalling that funding for these efforts are so sparse.
Fortunately, we have some time (maybe two years) before ultra-capable DNA printers hit the market, and one can hope that regulatory agencies will jump into the fray before that happens. For now, it’s still difficult to assemble entire genomes from individual pieces.
But what does it actually take to build a synthetic genome? Researchers often start with small DNA sequences and stitch them together into ‘megachunks’ — fragments that stretch 30-60 thousand bases in length — using enzymes. Dozens of short DNA strands can be stitched together in a single test tube to build entire viral genomes in one day, using dozens of individual pieces. Megachunks are next fed to Baker’s yeast, which use native machines to assemble the pieces into massive sequences that stretch 100,000 bases or more.
Hijacking yeast is a clever trick, but it’s not a panacea for genome synthesis. Yeast cannot stitch together DNA if a sequence has too many Gs or Cs, or lots of repetitive letters. Long DNA is also inherently fragile; removing a sequence from yeast, and sucking it up into a pipette, is often enough to shear and shatter the material.
This entire process is complicated by the fact that DNA assembly and genome design are rarefied skills, and there is a dearth of software to lower the entry barriers. Tools like Primerize make PCR a breeze for scientists. Where are the algorithms to speed up DNA assembly?
In general, we think that a shortage of funds has stifled innovation. Thousands of labs use PCR every day, but only a handful attempt to build genomes. It’s hard to win a federal grant based on hypothetical, but bold, aims; most labs are funded to do incremental work. But genome synthesis won’t get easier — and won’t be democratized — until DNA costs fall and governments push for solutions with serious dollars.
Finally, we need better tools to predict whether synthetic genomes will ‘boot up’ within living cells. As companies race to improve DNA synthesis itself, academics should strive to make predictive algorithms that can model how DNA will behave inside living cells.
After all, why spend millions of dollars and decades of labor if a synthetic genome doesn’t even work?
From Letters to Life
Metaphors in biology get a bad rap, but here’s another one: Cells are, in many ways, like cars.
Both are made from individual parts, unremarkable in isolation, that work together in symphony. A cell’s wall is the body that protects precious cargo. A cell’s genome is an engine, the beating heart. Glucose is gasoline, the raw spark that powers it all.
There is a brilliant synergy between mechanical parts within a car. We can hear the rattle of a shaky tire and smell the dying sputters of an overheated engine. Cells die, too, when their parts break. But unlike cars, which are made from bulky parts that can easily be swapped out with a wrench, cells are made out of microscopic machines. To change a cell, one must first identify the broken part, and then swap it out with dozens or hundreds of other parts, using trial-and-error tactics. Biological engineers basically take a throw-spaghetti-at-the-wall-and-see-what-sticks approach.
This analogy, of course, is a stretch. Cells are vastly more complex than automobiles, their parts are invisible, and life is made from thousands of individual molecules that operate within dense biochemical networks. Some parts of a cell’s blueprint — a.k.a. the genome — also seem to be written in an alien language; we’re unable to decipher the roles for hundreds of genes in well-studied microbes, including E. coli.
Life emerged on this planet more than 3.5 billion years ago, and evolution has slowly exerted its tendrils, like a marionette, ever since. Evolution has made cars — or cells — with fine-tuned engines and sleek bodies. Why, then, are we so ill-equipped to engineer or build cells in the same way that we can build a Porsche or Ferrari? When human minds attempt to match the prowess of evolution, our synthetic creations often fall terribly short, like a 1984 Corolla with a scratch down the side.
Still, there are reasons for optimism. Better tools to study biology, like powerful microscopes and clever sequencing techniques, have led to an exponential blossoming of biological data. We understand how biological parts function together — and how a synthetic genome sequence, found nowhere in nature, actually behaves — in more nuanced details than ever before.
Data, though, is not enough to fill in the missing gaps in our biological knowledge. It is one thing to study an organism that already exists, and quite another to make something that has never existed before; to veer off-script.
Building a synthetic cell, powered by a man-made genome, requires a deep knowledge of many things. For each and every gene, there are dozens of parameters to cram into a predictive computer model, including transcription, mRNA decay, translation, DNA supercoiling, transcriptional pausing, transcription termination, protein folding, RNA folding, transcriptional interference, genetic drift, and co-transcriptional translation. Yikes.
Synthetic DNA is also incredibly expensive (as we’ve discussed), and so we need to build predictive models that enable us to make a genome once, and only once. (The human genome, again, would cost about $300 million to synthesize.) That means we must get better at forward engineering; starting from a computer model and using its predictions to build parts that behave in desirable ways.
Unfortunately, the history of molecular biology is written the other way ‘round. Scientists typically observe a phenotype in nature, and then work backward to figure out why it exists, and which genes are responsible. Flipping science around yet again, to design genes that produce a specific phenotype, is no small feat.
First, we need to collect more data (and not just any data; more on that soon) to build predictive models. Then, we need to reconcile disparate datasets and incorporate them into a holistic, ‘digital’ view of life itself.
The Salis Lab at Penn State is best known for using biophysics and design automation to create biological parts — genes, promoters, ribosome binding sites (RBS) — on a computer. The RBS Calculator, first published in 2009, automatically designs DNA sequences that provide “rational control over the protein expression level.” In the last decade, this and other Salis Lab models have been used nearly a million times to engineer RBS sequences, promoters, gene regulators, highly non-repetitive DNA sequences, and riboswitches.
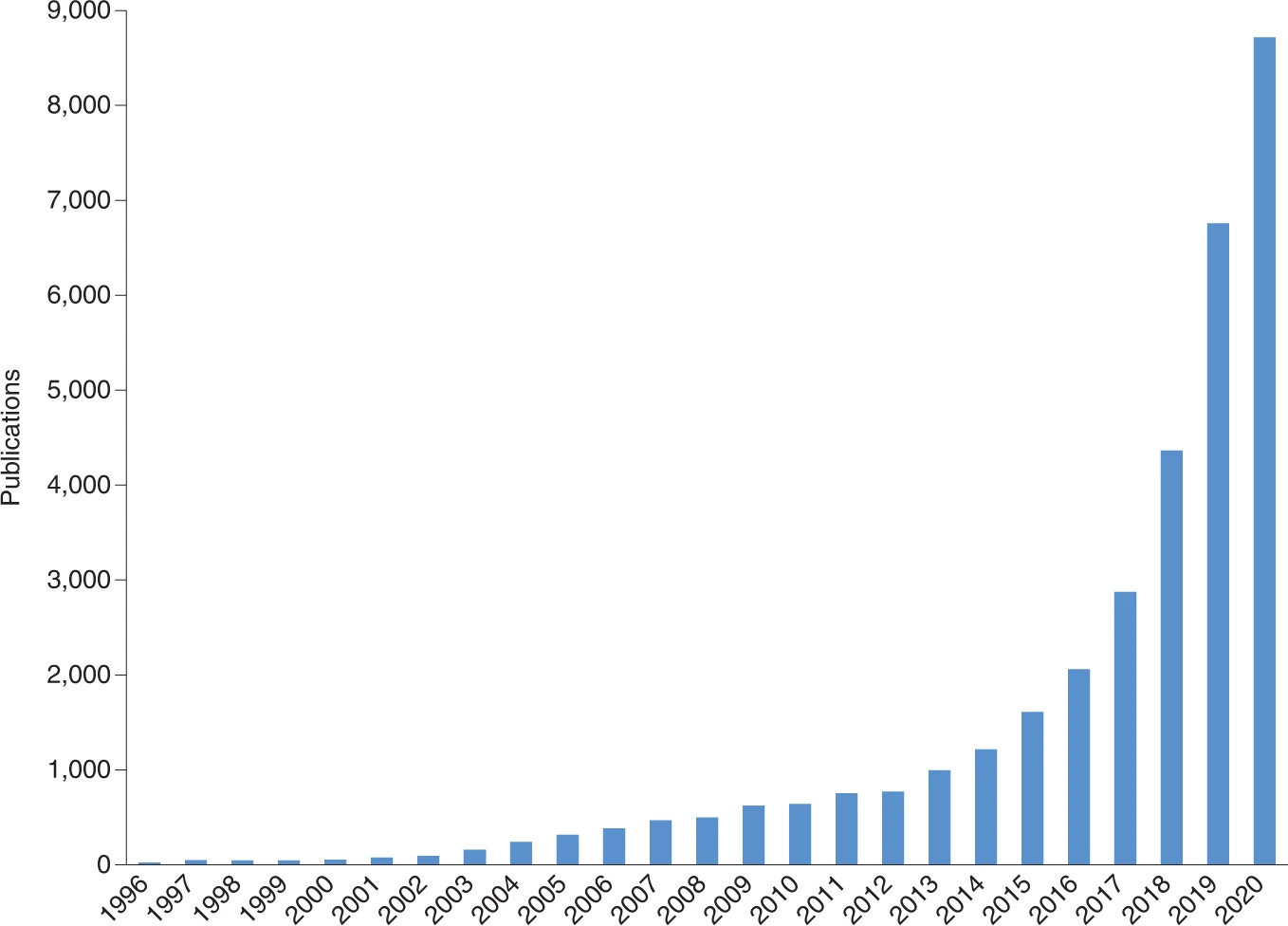
Each of these tools, though, can only design a very specific part, with a very specific function. The next intellectual leap toward writing entire genetic blueprints requires that we predict how a particular combination of manmade parts will work together to control the flow of genetic information in a cell. That is a vastly more ambitious aim, and Christopher Voigt and Markus Covert at MIT and Stanford, respectively, have made impressive efforts toward achieving it.
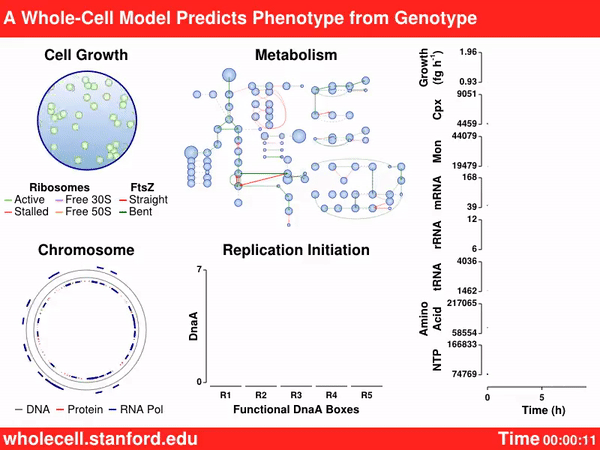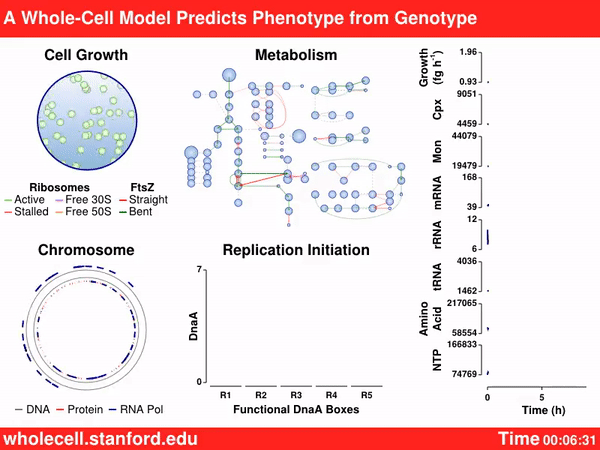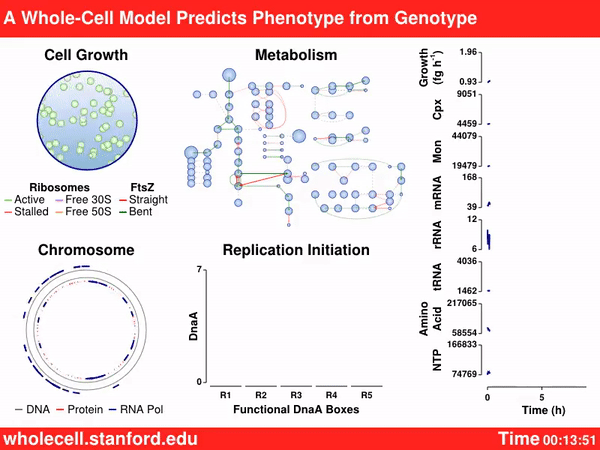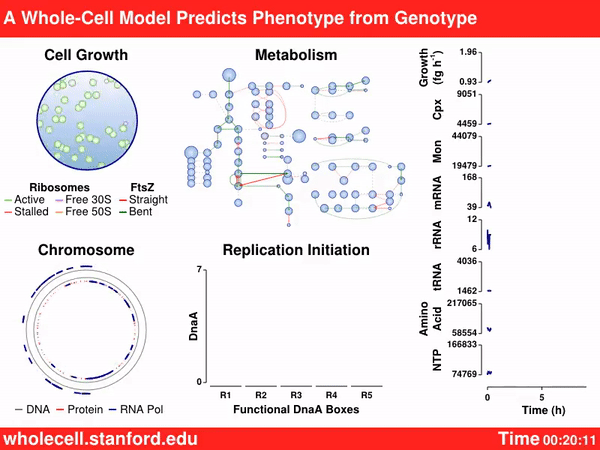
The Covert Lab is probably most famous for their computer model, developed in 2012, that simulated the entire Mycoplasma bacterial cell. That tool was powered by more than 1,900 parameters, collected from more than 900 papers, that describe 28 different biological processes in a living cell, including transcription, translation, mRNA decay, and many of the other things we mentioned earlier. That paper was the first demonstration of computational modeling as applied to whole-cell biology, but the model was never used to design or build new synthetic organisms. As recently as August 2022, Covert’s team expanded their work into E. coli, but the project is incomplete and monumentally difficult.
Just last month, the JCVI published the “most complete whole-cell computer simulation model” to-date for their synthetic organism, JCVI-syn3.0. The model is sensitive enough to predict how individual genes affect cell divisions. It predicted, for example, that adding in two specific genes, encoding enzymes involved in central metabolism, would decrease the times for cell division by 13 percent. When that prediction was tested in the lab, divisions dropped from 120 to 105 minutes, according to a press release.
The Voigt Lab at MIT also uses computational algorithms to design massive gene circuits, which perform like electric circuits, automatically. In 2016, new-to-nature circuits, made from 55 individual biological parts, were designed to sense and respond to ten different chemicals. The team computationally designed 60 different gene circuits and, of those, “45 circuits performed correctly.” All together, those circuits were constructed from a whopping 880,000 bases of DNA.
The Covert, JCVI and Voigt papers are extraordinary displays of our current capabilities. But, however impressive they seem, they are still akin to playthings in the grand context of a synthetic genome. If the JCVI model is truly our most complete digital rendering of a cell, then it’s just more evidence that we have very far to go. Their digital model simulates JCVI-syn3.0, an organism with just 452 genes. E. coli has more than ten times as many genes. It seems likely that whole-cell models will not be able forward engineer synthetic cells with thousands of custom parts within the next few years (but, please, prove us wrong).
There are, as we see it, at least two major problems that limit these predictive models. First, collecting the large amount of data needed to train these models is expensive, and quality standards for multiplexed assays are seemingly non-existent. Some people argue that “all papers should report data in absolute units,” but that’s not always needed. It’s often possible to convert arbitrary units (e.g. 10-fold increase in fluorescence) into absolute units if there is a common reference data point. What we actually need is better data, with more sensitive measurements, to make better predictive models.
Secondly, a research consortium should develop a centralized repository to store DNA sequences and link them with their measured outputs. Imagine if, for every DNA sequence that has ever been made and inserted into a cell, a database recorded details on the organism’s genome, how much protein was made from the DNA, the organism’s growth rate, and other parameters. All these data could then be fed into a machine learning model to enable more robust predictions of DNA sequence → expected behaviors within a cell.
As companies wrestle over DNA synthesis, academics should jump into computer modeling, AI, and data collection. They will find a vast, desolate landscape ripe for disruptive innovations.
Biology’s Future
Synthetic genomes are, in many ways, the final frontier in biology. To design a genome, insert it into cells, and boot up a new organism demands a breathtaking culmination of knowledge. How life works, how genes become proteins, how cells sense and respond to signals and, finally, how to emulate all of that to make a cell that has never existed before.
The stakes are huge; the aims worthwhile. Cells with rewired genomes could capture atmospheric carbon, degrade plastic waste in the ocean, deliver cancer therapeutics through the bloodstream, sculpt self-healing bridges, store exabytes of data, and create bio-renewable fuels. But this solarpunk vision requires a call to action; a herculean effort in science.
In some ways, it’s ironic that biology’s final frontier is less about biologists and more about everyone else. Synthetic cells need chemists to synthesize DNA, computational biologists to design DNA, and programmers to build software that makes everything work.
Currently, only a few labs focus on computational models and data collection, which are the core needs for future progress in synthetic genomes. The barrier to entry in this field is also high. DNA is expensive, and expertise in building genomes is quite a rare skill. To reach the next frontier, the field must progress in several key ways: Cheaper DNA, increased accuracy of part and system design, and automated tools for DNA cloning and gene assembly.

When the Human Genome Project launched in October 1990, its aims were, ostensibly, to map the human genome. The NIH said that they wanted to understand the letter-by-letter sequence for every inch of the Homo sapiens blueprint. But the project — which brought together thousands of scientists for more than a decade under a budget of nearly $3 billion — was not a success because of the sequence it unraveled.
No; the Project’s real triumph was the tools invented along the way, which culminated in a more than 10,000-times drop in DNA sequencing costs. The Human Genome Project offers a similar lesson for DNA synthesis. By setting a grand ambition and uniting broad swaths of scientists toward a common aim, barriers to entry will fall for everyone. Incumbents are removed from their proprietary thrones and fresh minds, with bold ideas, can enter into the fray. Now is the time for a grand scientific mission, with balanced risks and uncertain outcomes.
There is no greater ambition for biology’s future.
Thank you for reading.
Travis LaFleur is a PhD student in Howard Salis’ lab at Pennsylvania State University. He builds predictive models for synthetic biology using biophysics and machine learning.
Niko McCarty writes Codon and works at MIT. Find him on Twitter.
Correction: An earlier version of this post incorrectly suggested that Ansa is helping ACLID.bio to build their pathogen screening platform. We regret the error.
This is an amazing, comprehensive survey of what amounts to a fifth industrial revolution, moving in tandem with the developments in creating AGI. There are existential risks associated with both and this field needs someone like Nick Bostrom to produce a non-technical risk assessment comprehensible to the general public. Great job!
Extremely interesting overview!
I suspect that figuring out how genes behave will prove a far more daunting task than bringing down the costs of DNA printing. There are simply so many layers on top of the genome... People often talk about a "second genetic code," but to me it always felt like there was a "2nd, 3rd, 4th and nth genetic code"
I suppose that's where the advantage of fully synthetic cells lies. By starting from a "simplistic" (for biological standards) foundation that is extremely well-known and predictable, we can then build on top of that step by step in a similarly predicted fashion and tailor our synthetic organism to do exactly what we want. But to get all the wonders of life using this approach would be a lot like building them from scratch...
We'll probably always want to highjack naturally occuring biological systems in one way or another. They're just too powerful for us not to
The use AI models to predict the effects of large-scale genome engineering has interesting implications. Considering that AI models are increasingly afflicted by the "black boxes" problem as they grow larger, meaning that they may deliver accurate predictions but we may never know why, I suspect we may come create biological machines that we can't really understand. All we'll know is that our models told us that genome X would produce phenotype Y, and it works